How I decide what to work on and what to ignore
When I joined Clerk, the growth focus was in its early stages. There were a few active growth channels that averaged ~10 growth activities per month. As you can see from the image below, that volume quickly grew and I was, for the most part, at the helm of it all.
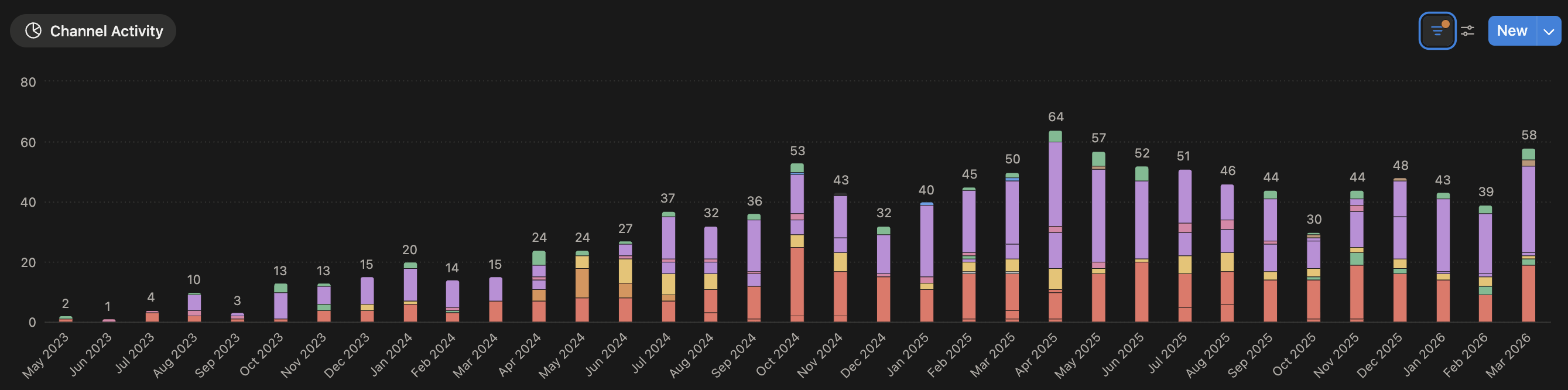
Within the first few months, I introduced several new channels including paid social, podcast sponsorships, and grew our existing presence in developer newsletters and open source integrations. It didn't take long until I was juggling experiments across a handful of channels and an even greater collection of individual partners.
Everything felt urgent because I was eager to understand what role each initiative played in influencing our growth metrics. I was also eager to prove my ability to make an impact as someone with an analytics background in more traditional marketing environments. As a team of one, I needed guidance on focus. That's where Impact Score came in.
What an Impact Score is
In prior roles, I had built a number of algorithms and formulas to assist in decision-making processes. This was no different.
The concept of an Impact Score is quite simple. It is a single number that lets you rank experiment ideas objectively. Gut feeling alone wasn't sufficient here since I was essentially adding to an incomplete foundation and our attribution data at the time was improving but relatively unreliable. Plus, gut instinct doesn't always work at high velocity or when it's one person's opinion. Keep in mind, this was all before the great AI wave, so I couldn't ask Claude or ChatGPT their opinion either.
The inputs
When building a decision-making formula, I use a blend of positive and contra inputs, since risk and reward are both naturally baked into any decision you make. Positive inputs are what you expect to get out of the experiment, whereas contra inputs are the cost of running it.
Positive Inputs
- Conversion Potential
- Reach
- Urgency
Conversion Potential was the most logical starting point. Will this experiment drive conversions for us? If not, then why are we doing it in the first place? A lower score for conversion potential could indicate this isn't a lower-funnel experiment. I manage the entire funnel, which includes running lots of TOFU (top-of-funnel) experiments to scale our overall reach. Scaling reach is just as important as running direct response, or BOFU (bottom-of-funnel) experiments. You need to consider magnitude, not just whether or not the experiment will generate results.
Reach is the estimate of how many people your experiment will reach. It helps inform magnitude as well.
- What is the estimated audience size we'll reach through this experiment?
- Is this a qualified audience or an experimental one?
- How much of the audience was I able to penetrate through the experiment?
You may naturally gravitate to larger scale experiments, but your success rate (or conversion potential) has a higher risk of being lower. It's good to find balance across the spectrum to hedge your big bets.
Urgency is if your experiment is time sensitive. Maybe you're running experiments tied to a launch or an event, moving the priority of that one up the board. Urgency can also be tied to what you expect to learn and whether it opens up meaningful opportunities downstream. Given that urgency is the input that tends to be most gamed or misapplied in practice — the "everything feels urgent" mindset — it's critical that this input is weighted based on true time-based constraints but can be easily overridden when needed.
Contra Inputs
- Investment
- Effort
Investment is the actual $'s we're spending on the experiment. It's essentially the direct contra of conversion potential and helps gauge whether we expect this experiment to be ROAS positive.
Effort is the internal cost of running the experiment. When planning any experiment, you need to understand if this is something you can run on your own or whether you need additional resources — either internally or externally. Also, is the experiment something that can be stood up quickly or will it require multiple planning cycles to get off the ground. Those two factors are generally correlated.
Together, these two contra inputs give you a good sense as to whether the juice is worth the squeeze.
In a sense, Impact Score in its totality acts as a profit & loss calculator.
I wanted the model to operate in a simple manner so each input has a magnitude scale of 1–3. A value of 1 for a positive input carries less weight than a value of 1 for a contra input. Meaning, if an experiment has a score of 1 for conversion potential, the overall impact score will likely be lower than an experiment where cost has a score of 1.
Here is an example of what an input scoring matrix could look like.

The formula
The inputs alone do not give you a viable scoring model. Each input is not equal to one another. You must introduce proper weighting based on which inputs are most important.

I applied the heaviest weights to Conversion Potential and Urgency with the contra inputs getting equal weight to one another. I did this because these inputs were the most critical to me. Conversion Potential is a given — I want to prioritize experiments with the greatest potential. Urgency trumps most other inputs if there are true time constraints. The contra inputs received equal rates because I didn't want these factors to dissuade me from running an experiment. These are hurdles that can be overcome, not deal breakers.
I didn't want an infinite scale so I adjusted percentage weights (e.g. 25% or 0.25) to simple decimals so the Impact Score range maxed out at 100.
Weighting not only allows me to prioritize the importance of each input but allows me to maintain a normalized measurable scale.
Impact Score in practice
Here's a real-life example of Impact Score in practice. This is a collection of experiments that are in our queue.
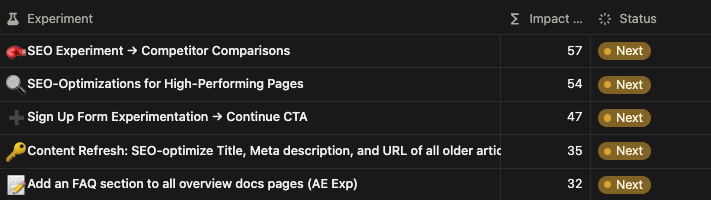
The top 3 experiments have similar conversion potential, but there are underlying differences that separate them. Notice the input scores for the two examples below. Our Sign Up Form experiment score is 10 points lower because it requires additional resources to launch and we are expecting lower reach, since it's not an outbound experiment.
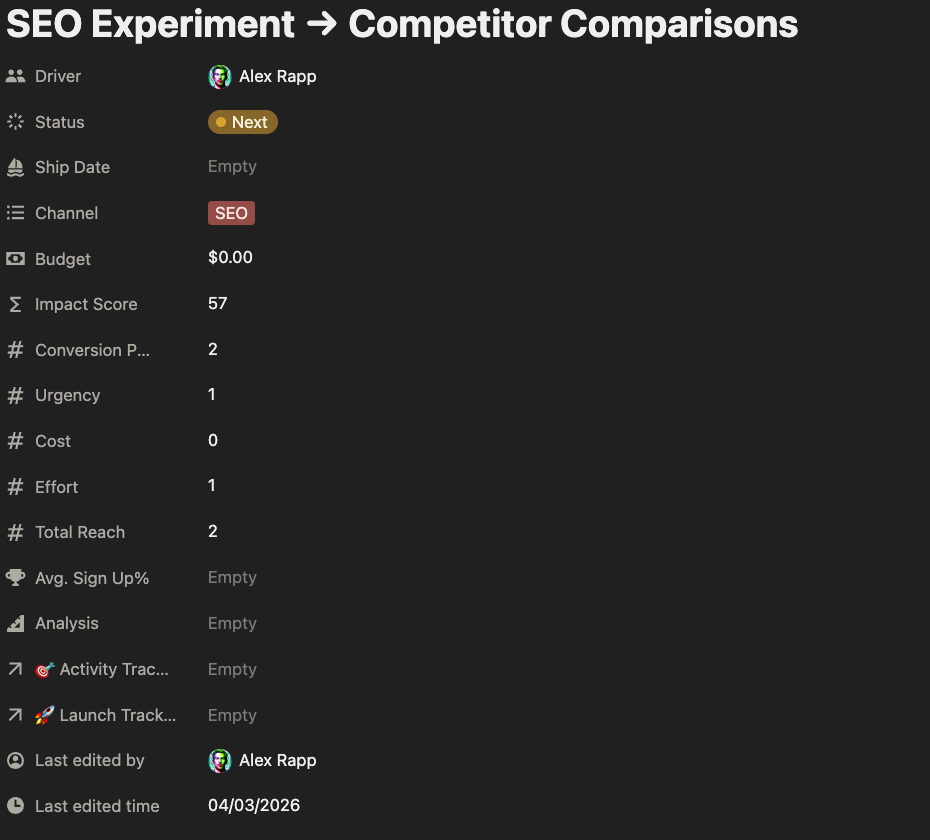
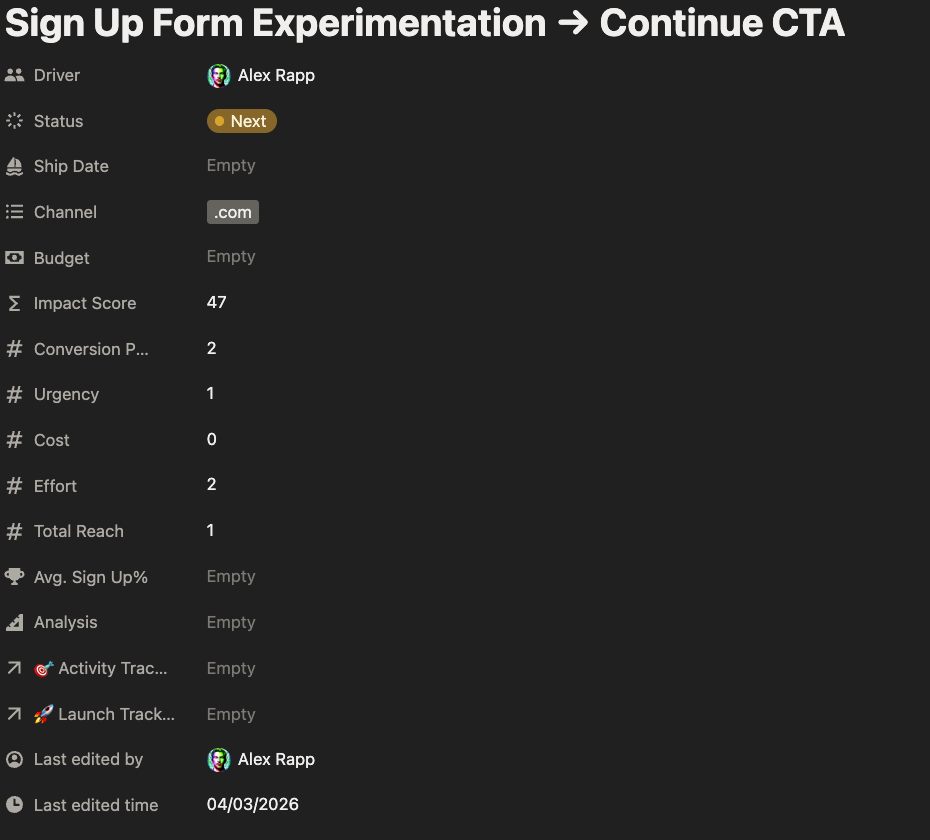
Each experiment is valuable in its own right, but I would prioritize the first two given their wider reach potential and the ability for me to run them independently.
What Impact Score doesn't solve for
Impact Score is not a catch all. It is not a replacement for judgment and is more so meant to provide guidance when needed. If there is a gut instinct that is contradictory to the score output, that can be an overriding factor. Robert De Niro's character in Ronin said it best: "Whenever there is any doubt, there is no doubt."

In other scenarios, Impact Score may be pushed aside if the experiment in question is related to something that's already in-flight. You'll naturally want to prioritize this experiment to batch learnings together into a cohesive summary. Impact Score may also be overridden if your experiment is simply exploratory. You might not have enough context to score an experiment in new territory accurately.
Impact Score also does not incorporate execution quality. When you're validating your inputs post-experiment, the score does not indicate how well you executed the experiment. A high-scoring experiment run in a sloppy manner can still be a time suck. The score has no opinion from that respect.
Input fidelity is not controlled. The score is only as reliable as the estimates going into the inputs. If your sense of reach is off or conversion potential is based on gut rather than data, the output is mathematical confidence on shaky ground. You need to have a strong data foundation to have implicit trust in your scoring model.
Finally, it doesn't account for portfolio-level balance. Impact Score is a local optimizer. It surfaces the highest-scoring individual experiments. It won't tell you if you're running 8 BOFU experiments and nothing that nurtures the top of funnel. It can produce a well-ranked list that still represents a poorly diversified portfolio.
Conclusion
Working at a startup or on a small team, you'll likely have lots of irons in the fire. Everything can feel urgent. Without a system, you default to whatever you think will make the biggest splash or whoever shouts the loudest from the powers that be. My goal is to launch at least 2 new experiments each week. Introducing Impact Score has allowed me to stay focused and prioritize what I expect to make the biggest impact on our KPIs.
Here's the playbook for creating your own Impact Score:
- Start by identifying your inputs
- Figure out your input scoring matrix
- Weight your inputs appropriately
- Test it!
If you're building your own Impact Score or if you have a different prioritization system, I'd love to hear what works for you.